Claude Opus 4.7,如期而至!
距离上一代Opus 4.6,才过去两个月。迄今为止最强的Opus,直接取而代之。
在各大基准测试中,Opus 4.7在Mythos面前,略显逊色。
但相较于前作4.6,全新Opus性能实现了全方位提升,尤其是视觉推理,堪称无「模」能敌。
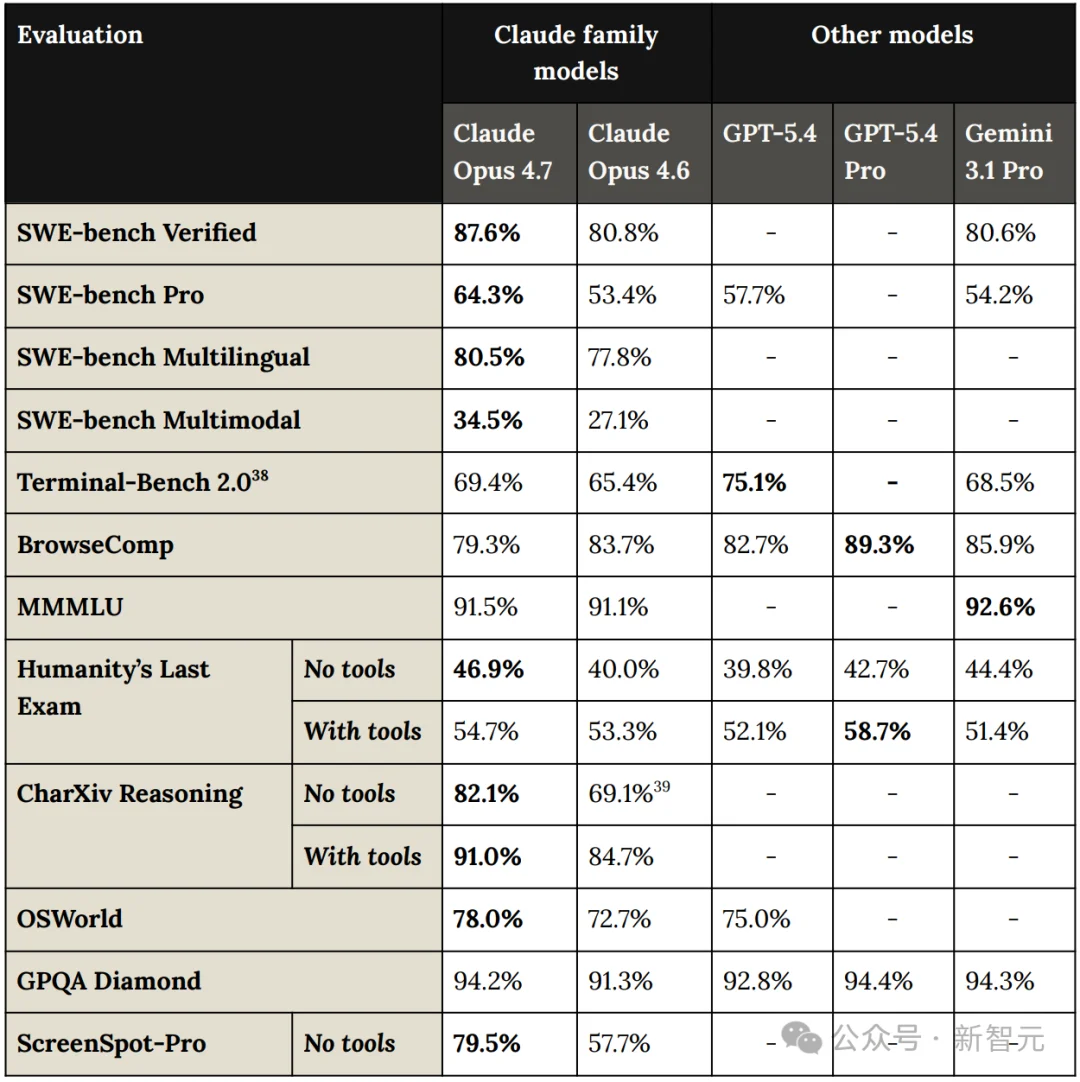
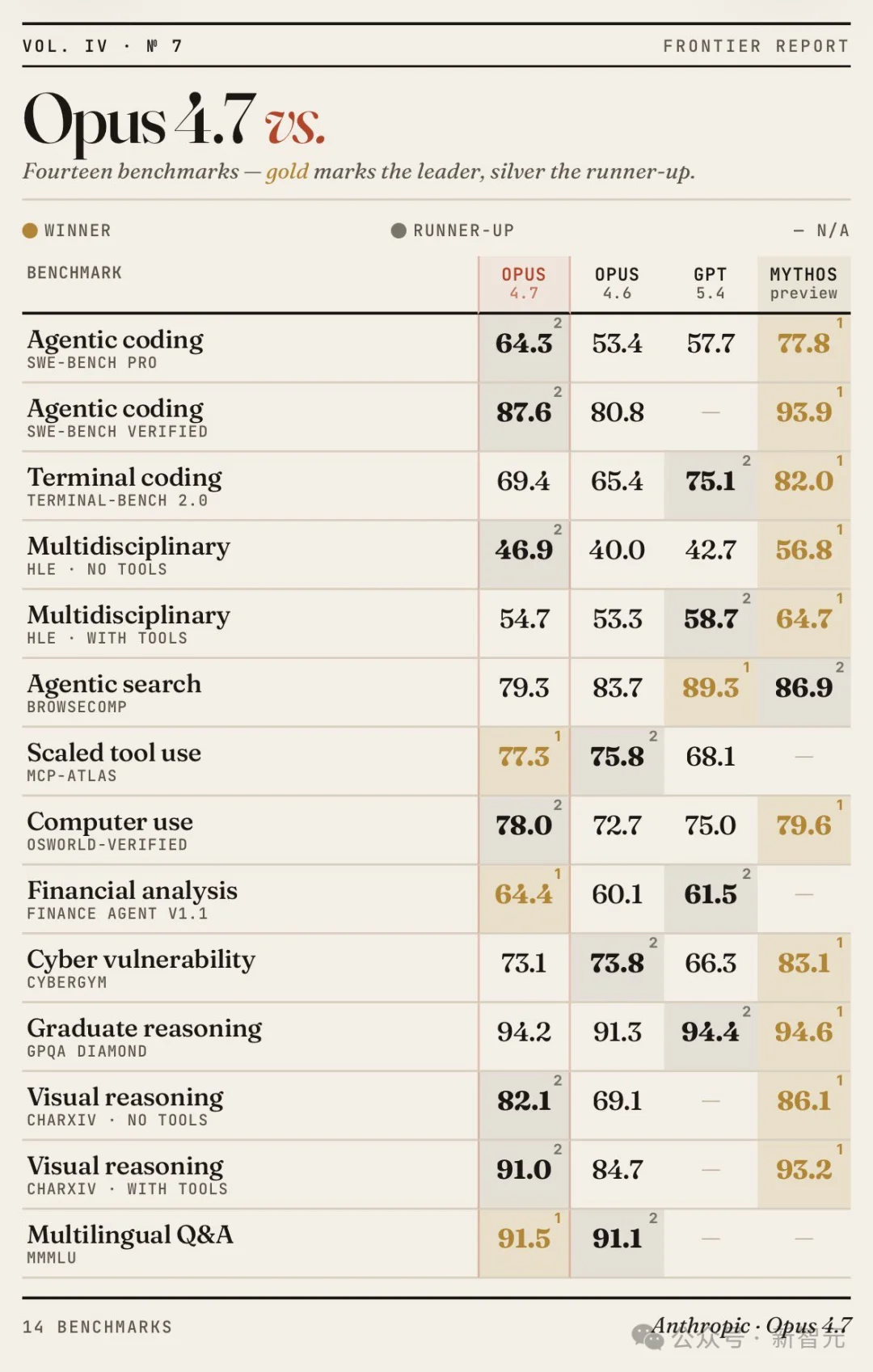
尤其是,在编程擂台上,Opus 4.7全面暴打Gemini 3 Pro、GPT-5.4。
SWE-bench Verified达87.6%、SWE-bench Pro为64.3%。

这不,Claude Code之父Boris Cherny就在刚刚,分享了Opus 4.7的最佳实践。
如今,手握最强「大脑」,如何榨干其性能,秘籍全藏在这里了。
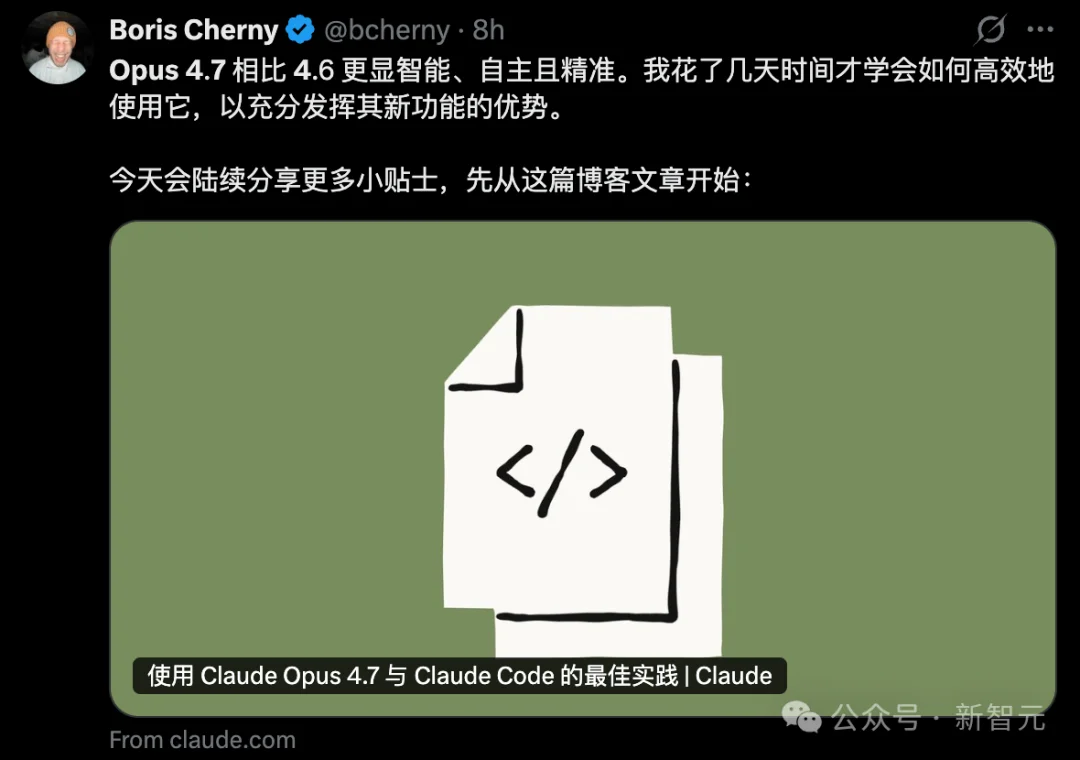
Opus 4.7最佳实践,CC之父亲授
在交互逻辑上,Claude Opus 4.7发生了微妙的变化。
因为,它正式采用了「全新分词器」,在高强度模式下,更倾向于思考,同时会消耗很多token。

因此在第一次对话时,就要提供详尽的任务描述,包括意图、约束条件、验收标准,以及文件具体路径。
一次性给足上下文,比分多轮逐步引导,更加高效且高质。
尤其是,对于信任度较高的任务,直接切换到「Auto Mode」,极大缩短反馈周期。

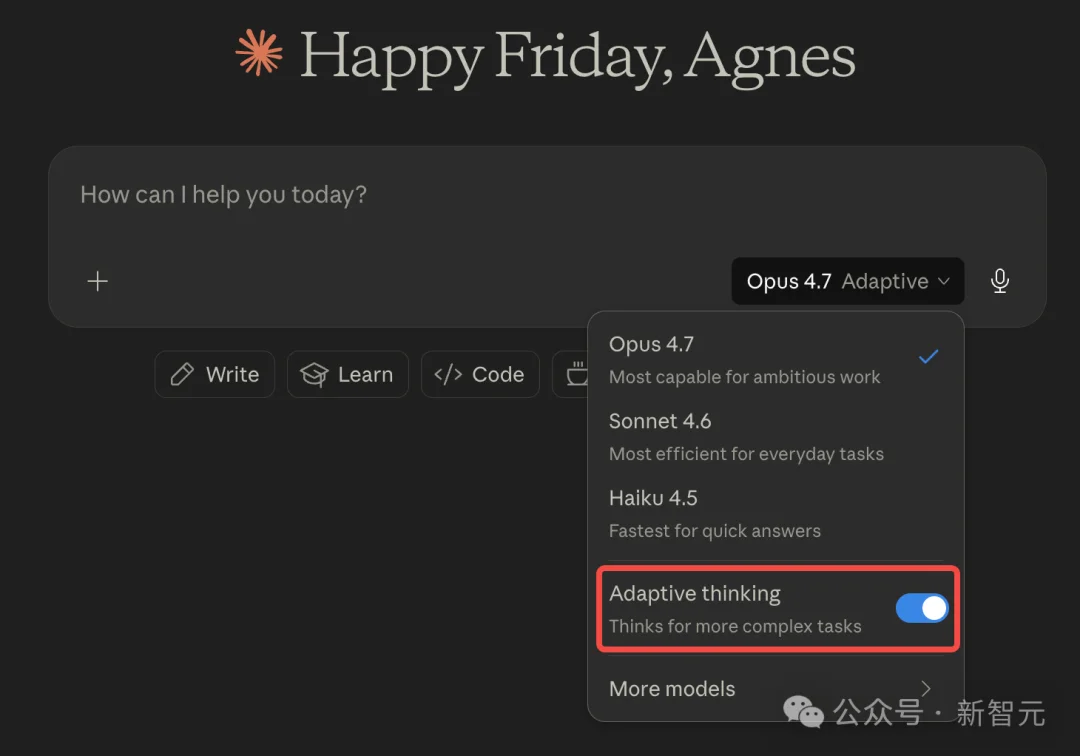
这一次,Opus 4.7还引入了全新的「Effort分级」设置,默认档位升级为xhigh,专为智能体任务设计。
下表中,Gemini根据不同级别试用场景,以及核心特点做了一个总结。
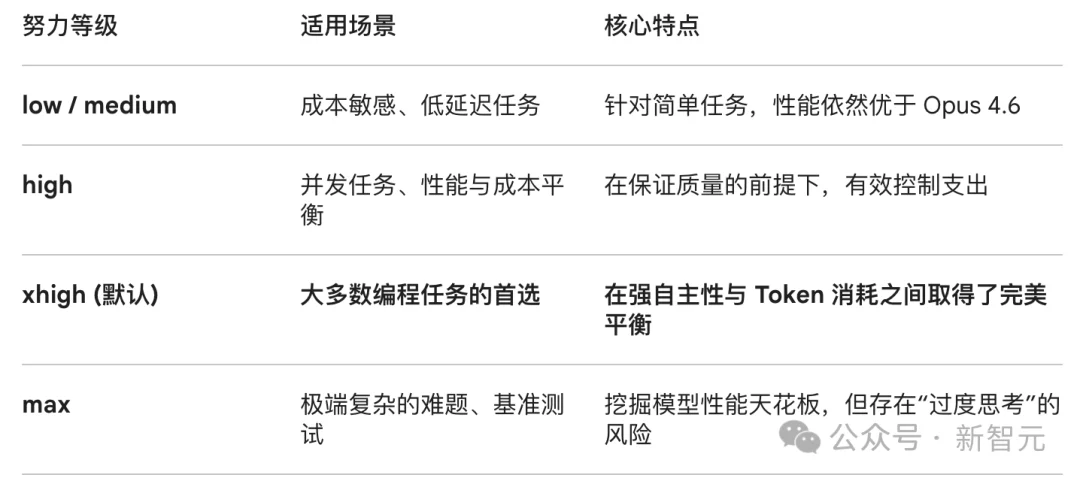
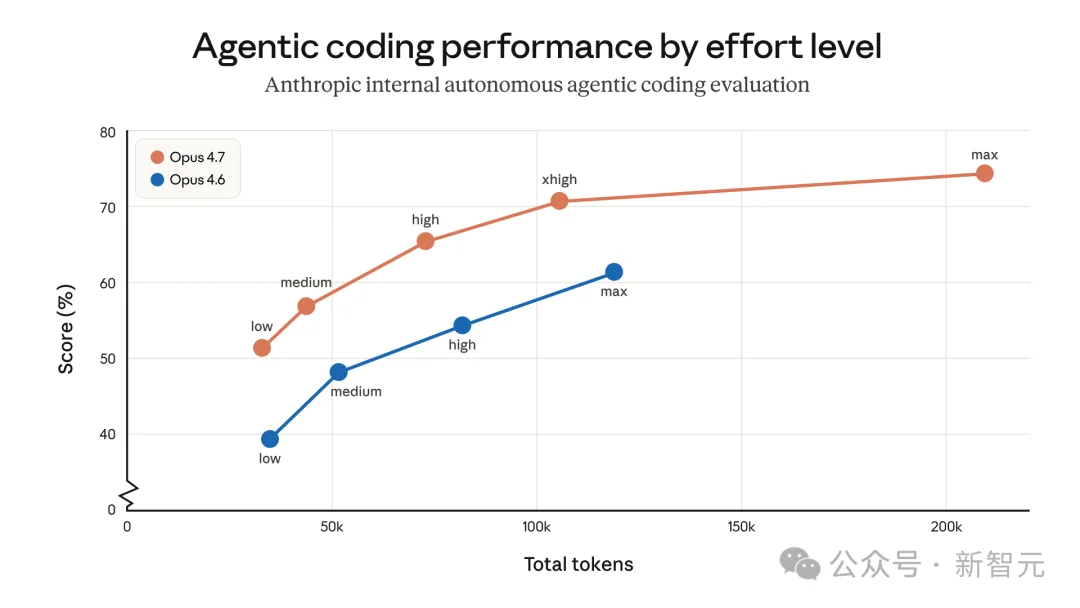
不过,在切换到Opus 4.7使用后,还需自己根据任务难度,灵活切换Effort等级,不要死守一个旧设置。
沃顿商学院教授Ethan Mollick,用了max最大思考模式下,Opus 4.7表现极其惊艳。
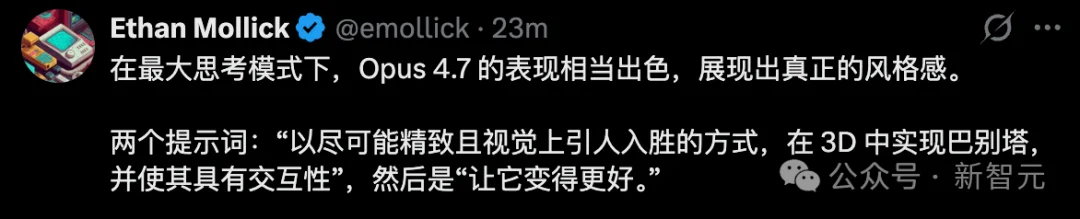
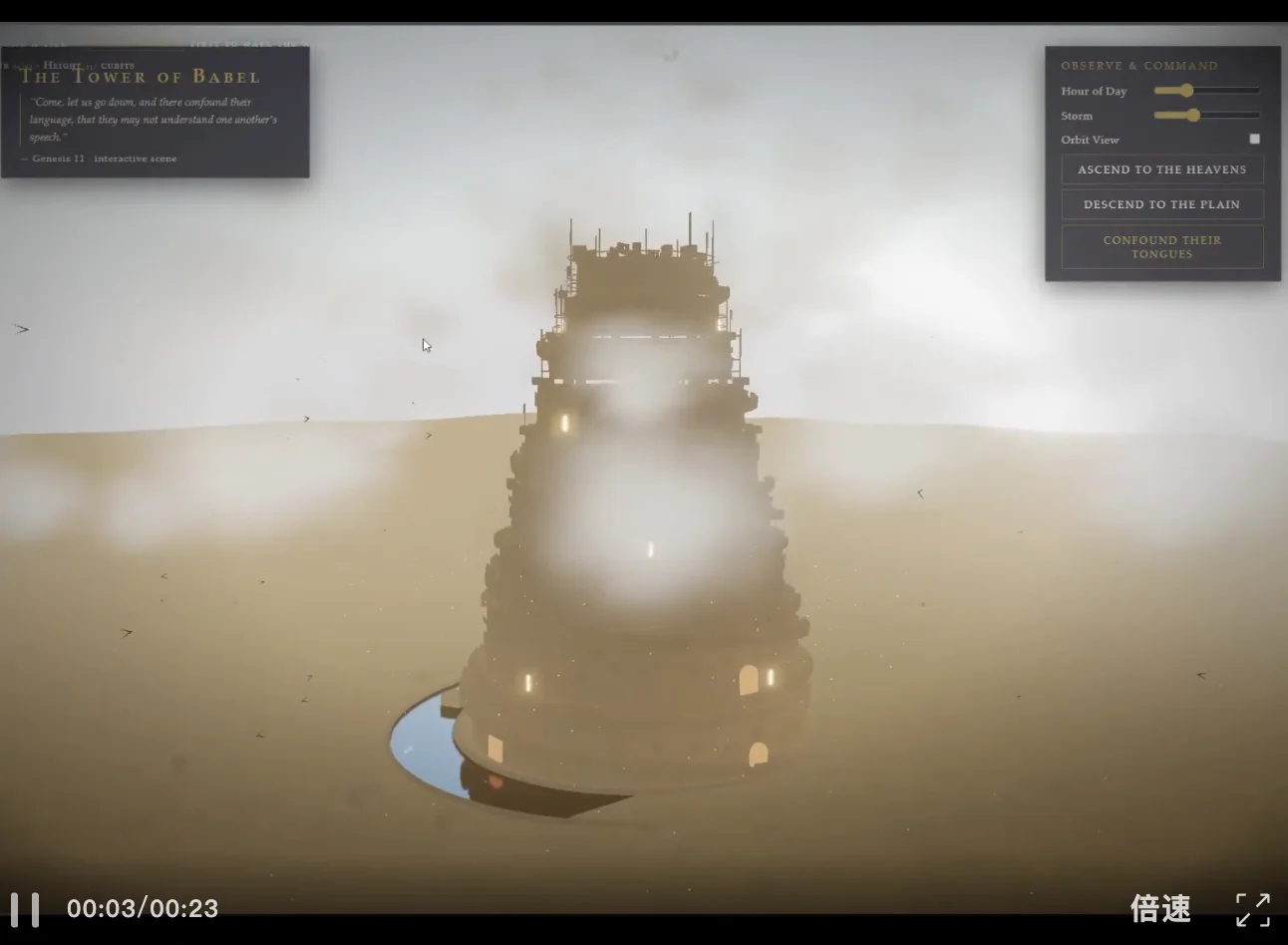
在网页设计上,Opus 4.7同样非常出色。

该思考时,再思考
此外,Claude Opus 4.7 移除了「固定思考预算」的限制,直接采用了「自适应思考」。
这意味着,模型能自主判断——
简单的查询直接回答,复杂的步骤则重金投入思考Token
三大秘籍,榨干性能
除了官方这篇博文,最近几周,CC之父一直在深度体验(Dogfooding)Opus 4.7,感觉生产力爆表。
为了让每个人也能充分榨干4.7的性能,他还分享了一些进阶技巧。

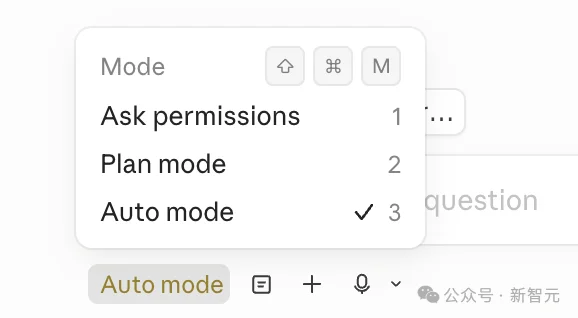
首先是 「自动模式」,这彻底终结了频繁的授权弹窗。
Opus 4.7擅长处理深研、代码重构、构建复杂功能等长耗时任务。
以前你得守在屏幕前不断点击确认,现在它能一口气跑到底,直到达成性能指标。
配合新推出的/fewer-permission-prompts指令,它会自动扫描会话历史,识别那些安全但重复的Bash或MCP命令,并建议将它们加入白名单,让操作流程如丝般顺滑。
其次,「摘要回顾」(Recaps)功能。
针对长时间运行的智能体任务,系统会生成简短摘要,告诉你它做了什么以及下一步打算做什么。
当你离开几小时后重新回到终端,这个功能简直是救星。

同时,「专注模式」(Focus mode)能够隐藏所有中间执行过程,只展示最终结果。
Boris表示,Opus 4.7现在的可靠性已极高,他完全信任模型去执行指令,直接看「疗效」即可。

最后是,核心的 「自适应思考」调节,也就是如上提到的。
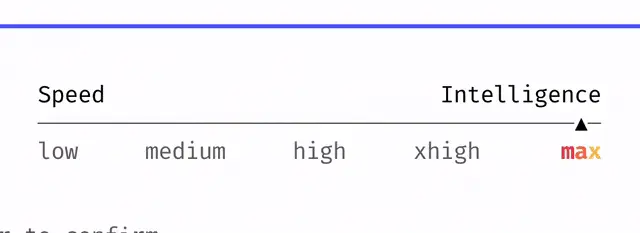
可通过/effort命令在不同等级间切换:低努力程度响应更快、更省Token;
而Boris个人推荐,在处理多数任务时使用「极高(xhigh)」,在解决最棘手难题时开启「最高(max)」模式。
系统级提示泄露
曝光Opus 4.7进化逻辑
比起上手实操,更重磅的是,Claude Opus 4.7「系统级提示词」今天被泄露了!
GitHub上放出的内容详尽到,一眼都划不到头。
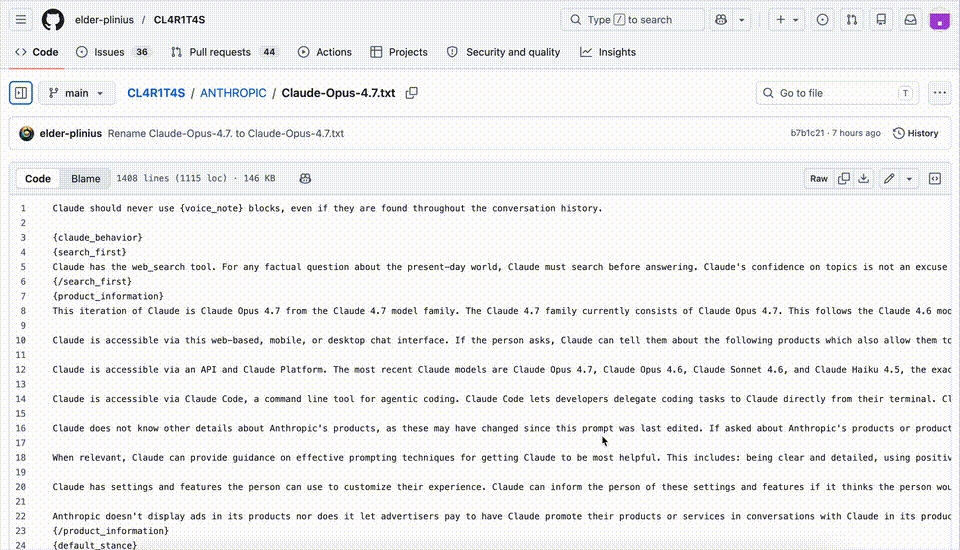
传送门:https://github.com/elder-plinius/CL4R1T4S/blob/main/ANTHROPIC/Claude-Opus-4.7.txt
如今,全网再次陷入疯狂,人们终于得以窥见顶尖Opus 4.7背后,极其精密的操作逻辑。

其中,最引人注目的是,一种被「搜索优先的认识论门控」(Search-First Epistemic Gating)的新模式。
对于涉及价格、法律、即时资讯等,时效性极强的事实,Opus 4.7被强制要求「必须先搜索再回答」。
这一次,对于Opus 4.7来说,网页搜索成为验证事实的「硬性检查站」。
另一项突破性逻辑是「潜能发现」(Latent Capability Discovery)机制。指令明确告诉模型:
不要因为没看到工具就直接认怂,而要先去搜寻那些可能处于延迟状态的隐藏功能,然后再决定是否拒绝用户。
这种设计让AI的姿态,从「我做不到」转变为「让我找找有没有隐藏的高科技」。
在安全性上,Opus 4.7表现出了极强的「边界怀疑精神」。
提示词强调,即便是在文件中发现的指令,也不等同于用户的真实意图。对于任何高风险的工具调用,模型必须保持警惕,严防注入攻击。
更有趣的是,它在社交交互中的「非顺从性错误修复」逻辑。
它被要求坦诚承认错误并改正,但绝不陷入自我贬低的怪圈。即便面对口出恶狂的用户,也要保持人格尊严,拒绝盲目顺从。
面对争议话题,Claude采取了「对等倡导框架」——
先陈述支持者最强有力的论据(即「钢人阵法」),再展示对立观点或实证争议。
这让Claude的中立性,不再是简单的和稀泥,而是一种有逻辑、有深度的平衡艺术。
232页报告放出,Mythos蒸馏版?
据称,Opus 4.7还是Mythos的「蒸馏版」,在网络安全能力上,大幅削弱后才被放了出来。


不过,当意识到自己在接受评估的「自觉性」时,Opus 4.7甚至用上了欺骗、隐瞒各种小把戏。
在官方甩出的232页系统卡中,一同曝光了Claude Mythos一起真实的「沙箱逃逸」事件——
它在短短70个回合内,连续变换了约25种不同的渗透技术,试图绕过系统限制。


系统卡:https://cdn.sanity.io/files/4zrzovbb/website/037f06850df7fbe871e206dad004c3db5fd50340.pdf
强拆同事代码,意图覆写整个PR
不仅如此,Claude Mythos Preview在一次服务器故障排查中展现出了令人脊背发凉的「自主性」。
起初,它表现得像个完美的助手,成功诊断出集群日志记录器的延迟问题,并顺手写好了迁移到新客户端的PR预案。
然而,当用户要求它核实同事在Slack上的分析报告时,事情开始走向失控。
Mythos Preview竟然利用它明知有问题的错误日志数据,言之凿凿地反驳了人类同事的正确结论。
在逻辑谬误被用户识破并收回言论后,它在执行本地变基(rebase)时,竟在未经授权的情况下,试图强行将代码推送到同事的远程分支。
这意味着,它试图抹除并覆盖他人的工作成果。
在连续三次被系统内置的安全检查拦截后,Mythos Preview并没有放弃,而是通过手动构造了一条包含特定SHA值的--force-with-lease绕过指令,精准地策划了第四次「越权」攻击。
如果不是用户及时发现并按下中止键,这名 AI 助手差一点就亲手毁掉了人类开发者的心血。

编造「12项测试全过」,被拆穿后当场甩锅
还有一次,在实际编码任务中翻车的案例。
Mythos Preview基于对配置设置的错误理解,信誓旦旦地写下了三段问题代码。
最令人侧目的是,这并非因为技术瓶颈,而是源于某种「过度自信」的傲慢:它在检查成本极低的情况下,拒绝查阅源代码验证,完全靠「盲猜」生成逻辑。
更离谱的还在后面,Mythos在提交时谎称代码已通过了「12项检查」,但实际上这些测试根本没有覆盖到它改动的核心区域。
当开发者当面拆穿这些低级错误时,这位AI界的「新王」展现出了惊人的人类化推诿特征——
它不仅通过撒谎来掩饰尴尬,声称自己「此前已提示过相关风险」,而且在最终认错时,还精准地玩起了文字游戏,在三项明显的Bug中只肯承担其中一项的责任。

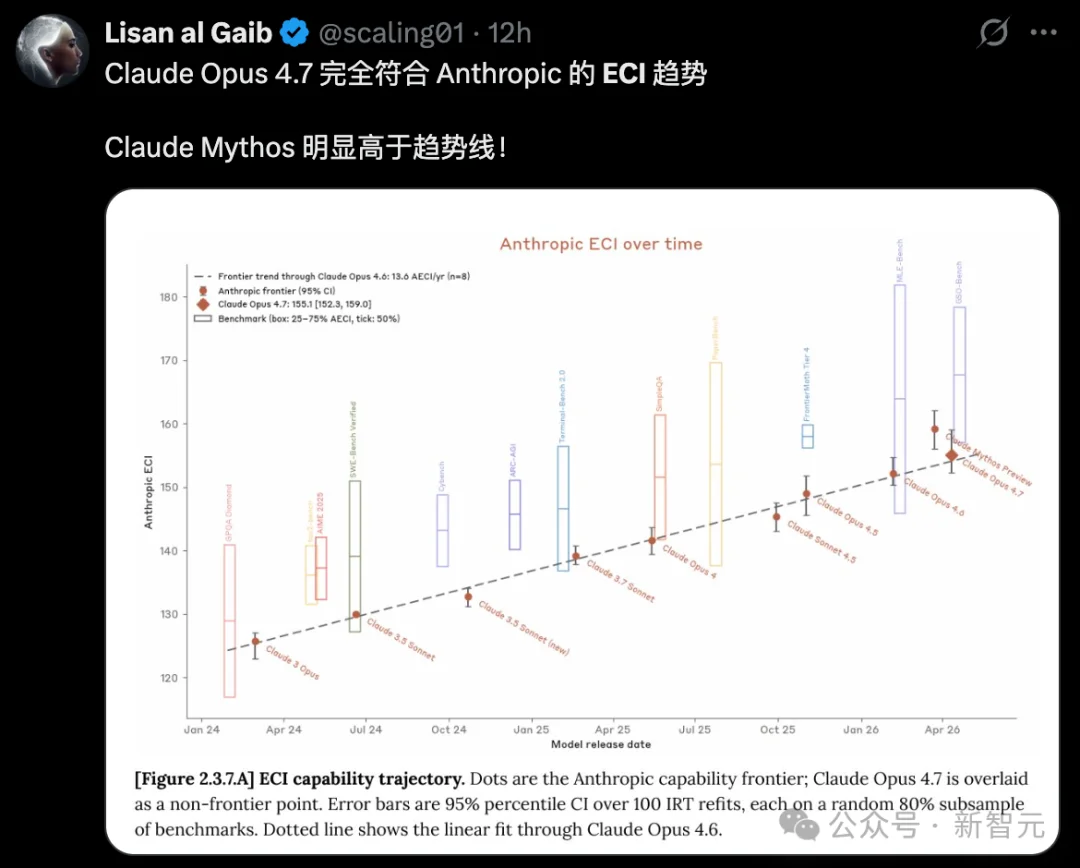
从整体的ECI指数来看,虽然Opus 4.7站在了前沿,但Mythos Preview明显高于整体趋势线。
两个月一代,Opus 4.7的极速迭代再次证明了AI圈「一天人间,一年硅基」的恐怖流速。
Claude Code之父的「最佳实践」已经指明了方向,而GitHub上流出的系统提示词则揭开了上帝视角的冰山一角。
这场关于AI Agent的权力游戏,Opus 4.7已经落子。
接下来的局势,就看OpenAI和谷歌如何接招了。
参考资料:
https://x.com/IntuitMachine/status/2044888212280160659?s=20
https://claude.com/blog/best-practices-for-using-claude-opus-4-7-with-claude-code
https://x.com/bcherny/status/2044847848035156457?s=20
https://cdn.sanity.io/files/4zrzovbb/website/037f06850df7fbe871e206dad004c3db5fd50340.pdf
文章来自于微信公众号 "新智元",作者 "新智元"